Time Complexity and Logarithms
I've been practicing evaluating time complexity with Big O notation, and while I can intuitively recognize when an algorithm runs in linear time, constant time, or quadratic time, I've not been able to intuit why and when a runtime is O(log n) or O(n log n).
Until today! So here are some notes that hopefully will be helpful for understanding why a program has a time complexity of some factor of log n. I'm still new to this and my math skills are rusty, so if I've made a mistake, please yell at me on Twitter so I can correct it.
What's a Logarithm Anyway?
"The logarithm is the inverse operation to exponentiation"1. In other words, the logarithm of a number is the exponent to which a base number must be raised to to get that number. It's like reverse engineering exponentiation, if you will.
I think it's easiest to understand after seeing a few examples:
- log10 100 = 2
- log3 81 = 4
- log1 1 = 1
- log 100 = 2
For the first example, the base base is 10 and the logarithm is 2, because the goal is to figure out what number x will make 10x yield 100. In this case it's 2.
Note that base-10 logarithms are known as common logarithms and are often represented without specifying the base. So examples 1 and 4 are actually the same expression just represested differently.
Big O Notation Refresher
(You can skip this if you're already comfortable with Big O Notation)
When evaluating an algorithm, it's often helpful to think about how it will scale as the number of inputs (n) increases toward infinity. A program may be fast with 10 inputs, but what happens when it has 1,000 or 1,000,000 inputs?
That's what Big O notation helps us reason about. For example, this programs runtime is O(n), aka linear time, because as the number of inputs, n, increases, the runtime is proportional to n.
let arr = [1, 2, 3, 4]
for (let i = 0; i < arr.length; i ++) {
console.log(arr[i])
}
And this program's runtime is O(n2), otherwise known as quadratic time, because for each input element, it iterates through the inputs again, thus requiring n2 iterations.
let arr = [1, 2, 3, 4]
for (let i = 0; i < arr.length; i++) {
for (let j = 0; j < arr.length; j++) {
console.log(arr[j])
}
}
O(log n)
While O(n) and O(n2) runtimes aren't too difficult to reason about, log n is a little trickier to understand intuitively (at least for me).
Let's start out by looking at a table that shows some possible solutions for the following formula:
log10 x = y
| x | y |
|---|---|
| 1 | 0 |
| 10 | 1 |
| 100 | 2 |
| 1,000 | 3 |
| 10,000 | 4 |
To say that a program that runs in O(log n) time is to say that if we replace x and y with the number of inputs (n) and time respectively, when we evaluate how fast the program runs as n approaches infinity, it resembles the pattern in the table above.
| n | time |
|---|---|
| 1 | 0 |
| 10 | 1 |
| 100 | 2 |
| 1,000 | 3 |
| 10,000 | 4 |
In other words, as the the number of inputs increase multiplicatively, the time increases linearly. That's a great runtime!
Recognizing O(log n) in the Wild
So where might one find this sort of runtime? In all sorts of algorithms, including binary search which I think is pretty easy to visualize and intuit.
Consider this binary search tree. The sorted array it represents is [1, 3, 4, 6, 7, 8, 10, 13, 14].
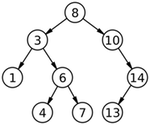
Let's say that we're searching for 13 in this tree. We start at the root, 8, then take a "divide and conquer approach" and at each node we compare the node to 13. If they're equal, the search is over, if the node is greater than 13, we search the left subtree, if it's less than 13, we search the right subtree.
Divide and Conquer
What's important to notice is that at each iteration, half of the remaining nodes to consider are eliminated. So even if the tree's depth is expanded by 1, that only adds one more iteration to the worst-case scenario of searching for an element that happens to be a leaf node (a node with no children).
If we construct a table with the number of elements in a binary search tree (in which all non-leaf nodes have two children) and consider how many iterations would be required to find a specific leaf node, we can see that it resembles the tables we used to represent a logarithm.
| n | time |
|---|---|
| 1 | 1 |
| 3 | 2 |
| 7 | 3 |
| 15 | 4 |
| 31 | 5 |
| 63 | 6 |
So the quick and dirty way I've been going about recognizing O(log n) operations is by asking myself what happens if I were to increase the number of inputs multiplicatively. If the runtime increases linearly, then I know its time complexity is O(log n) or some factor of O(log n).